When the RAID array on NAS Promise SmartStor Zero becomes degraded or corrupted, access to your data may be lost instantly. RAID 1 mirror failure, disk desynchronization, or metadata corruption are among the most common issues. This guide explores typical RAID failures affecting the NAS Promise SmartStor Zero and how to recover data without rebuilding the array incorrectly.

Hardware Overview of NAS Promise SmartStor Zero
The Promise SmartStor Zero NAS comes with 2 drive slots, making it a simple and reliable solution for everyday storage needs. Even if you’re new to NAS devices, the setup is straightforward: install your drives, choose RAID 0 for speed or RAID 1 for safety, and you're ready to go. The system uses either EXT4 or Btrfs file formats, both designed to keep your files organized and protected.
If something goes wrong—like a disk failure or accidental deletion—understanding these basic technical details helps you restore your data more effectively.
Technical Aspects of Data Recovery on Promise SmartStor Zero
The Promise SmartStor Zero architecture relies on two-disk RAID layouts, typically RAID 0 (striping) or RAID 1 (mirroring). Data recovery requires rebuilding metadata structures from EXT4 or Btrfs volumes, interpreting RAID parameters, and restoring logical block mapping. RAID 0 presents the highest risk due to the absence of redundancy, while RAID 1 allows partial reconstruction even when one drive is degraded. Advanced cases involve partition table corruption, DSM filesystem issues, and scenarios where both disks enter “crashed” state.
Main Features of the Promise SmartStor Zero NAS
| Drive Bays | Supported Drives | Hot Swappable | Supported RAID | File Systems | Maximum volume |
| 2 | 2.5" or 3.5" SATA | ✓ | RAID 0, RAID 1 | EXT4 | 4 Tb |
As configured with a RAID 1 mirror using an EXT4 filesystem on a Linux-based device driven by a Marvell Kirkwood processor with 256MB of RAM and no SSD cache, the storage architecture prioritizes on-disk redundancy while relying on limited system resources for journaling and metadata management. The single most probable model-specific failure point is EXT4 journal or metadata inconsistency under sustained write activity or abrupt interruption: constrained memory can delay or fragment write commitments and leave filesystem structures partially updated across the mirrored devices.
When the journal or metadata is left in an indeterminate state the filesystem cannot be cleanly mounted and the logical directory tree becomes inaccessible even though physical block copies remain. The recovery principle outside the NAS is to export the raw drives to an external Linux-based environment, reconstruct the RAID 1 mirror at the block level, and perform EXT4-aware journal replay and metadata reconstruction operations against copies rather than the originals; extract files from a verified read-only mount and validate integrity before any in-place repair.
Advanced NAS Recovery Workflow for 2-Disk Systems
When a 2-disk NAS fails — whether due to RAID degradation, accidental deletion, corrupted partitions or an unexpected power loss — you can still recover your files using a structured, technician-level workflow. Follow this detailed procedure to safely rebuild the RAID and extract your data.
-
Step 1 Power down the NAS and remove both drives.
Shut the unit down completely, disconnect all cables and carefully slide out the disks. Label them “Disk 1” and “Disk 2” to preserve the original RAID ordering, which is crucial for accurate reconstruction.
-
Step 2 Attach the disks directly to a PC.
Use SATA ports whenever possible for stable I/O throughput. Both disks must be connected simultaneously — NAS RAID cannot be rebuilt using single-drive access.
-
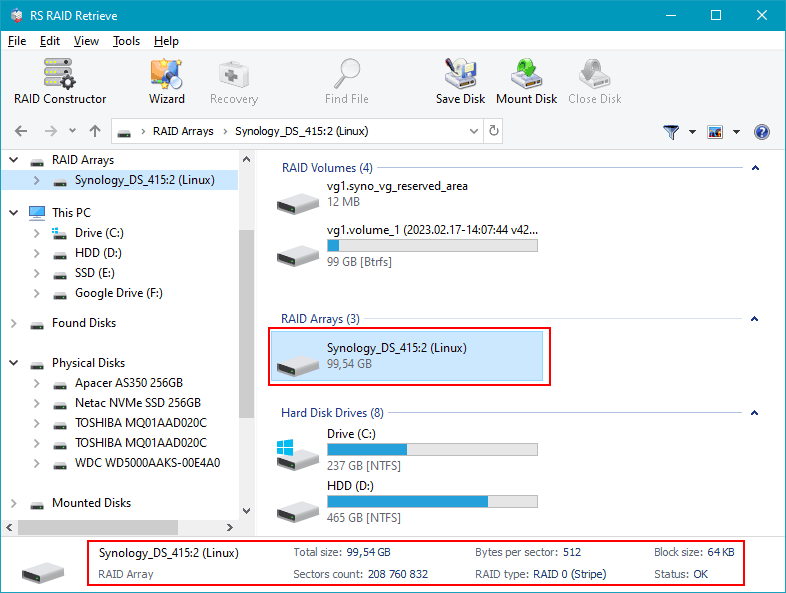
Step 3 Launch RS Raid Retrieve and load the drives.
The software will read RAID metadata, internal partition tables and filesystem signatures (EXT4, XFS, Btrfs). It reconstructs the original RAID configuration automatically but allows manual correction for expert users.

Data recovery from damaged RAID arrays
Available for: Windows, macOS, Linux -
Step 4 Verify RAID parameters detected by the software.
Check strip size, disk order, parity rotation and block alignment. Incorrect parameters cause incomplete folder structures or unreadable files, so validate them carefully.
-
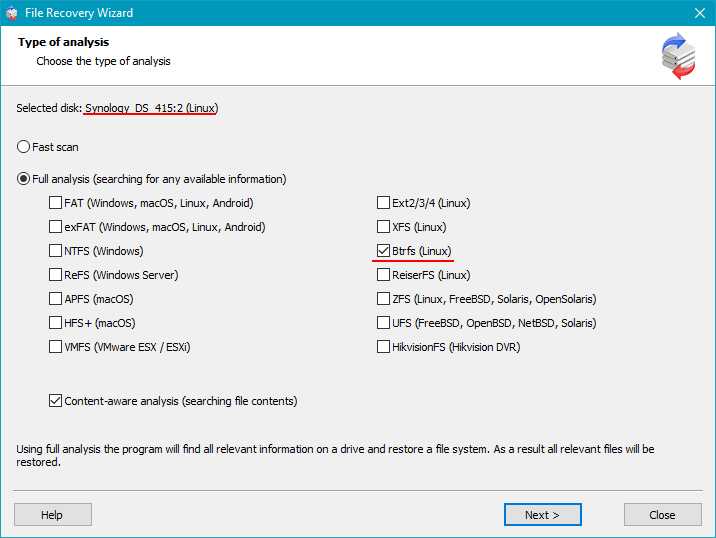
Step 5 Begin a full deep scan.
The program analyzes both disks sector-by-sector, reconstructs directory trees and identifies fragmented or deleted items. Deep analysis is recommended for damaged NAS volumes.
-
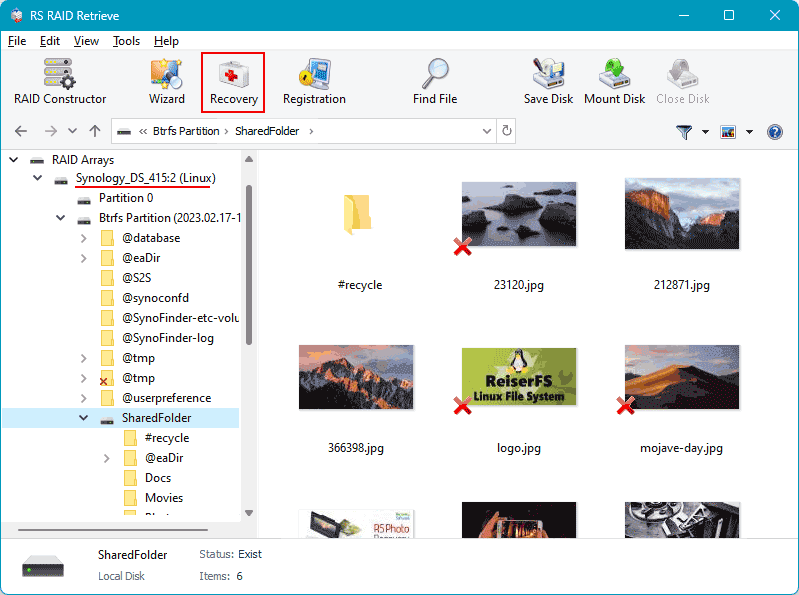
Step 6 Review detected files and validate recovered structures.
Open folders, preview thumbnails, and ensure key documents, virtual machine images, photos and multimedia content are present.
-
Step 7 Export your recovered data.
Always save files to a different drive — never to the original NAS disks — to prevent overwriting data remnants.
Tip: Avoid rebuilding the RAID inside the NAS until you’ve created a full backup of the recovered data.
Technician-Level Causes of RAID Failure in NAS Promise SmartStor Zero
In two-disk NAS systems such as NAS Promise SmartStor Zero, RAID degradation is typically the result of predictable mechanical, logical, or operational faults. From a technician’s perspective, each failure scenario presents a set of identifiable indicators, allowing structured diagnostics and controlled data-recovery workflow.
Drive desynchronization under continuous workload. Long-term operation causes sector reallocation, uneven read delays, and latency spikes. When one disk falls behind the RAID controller’s timing thresholds, the array marks it as out-of-sync, initiating a degraded state.
Unrecoverable Read Errors (URE) during resync. Two-bay systems using RAID 1 or RAID 0 are highly sensitive to URE. If a disk develops unreadable blocks during reconstruction, the process halts, resulting in a failed volume.
Thermal instability inside compact NAS chassis. Poor airflow, clogged vents, or aging cooling systems elevate temperature. Drives operating outside optimal thermal parameters demonstrate increased write errors and mechanical instability.
Controller-level inconsistencies. Firmware aging, interrupted writes, or voltage fluctuations lead to metadata corruption, causing RAID misalignment. Once the controller cannot match parity or mirror mapping, the array enters failure mode.
- Sector-level delays and SMART warnings accumulate unnoticed over weeks;
- Filesystem metadata desynchronizes after abrupt power loss or improper shutdown;
- Disks with different wear levels diverge in I/O throughput, accelerating RAID degradation.
This set of failure patterns is standard for NAS Promise SmartStor Zero devices, and each requires targeted recovery actions, sector-by-sector imaging, and controlled RAID reconstruction.
Common Causes of Data Loss in NAS Devices
Data loss in NAS systems often occurs due to RAID failures, accidental deletion, firmware corruption, disk degradation, and power outages. Misconfigured RAID arrays or simultaneous disk failures also frequently lead to inaccessible volumes or damaged file structures.






